

📘学习资源分享h3
- 🔗 【10分钟讲清楚 Prompt, Agent, MCP 是什么】
- 🔗💗 什么是Function Calling与MCP协议?它们为何要这样设计?
- 🔗💗 Function Calling 与 MCP 协议|深究 MCP 协议的设计,密码:4892@u29
- 🔗 MCP是怎么对接大模型的?抓取AI提示词,拆解MCP的底层原理
- 🔗 手把手彻底学会 Agent Skills!【小白教程】
- 🔗 什么是大模型Skill 10分钟弄懂
- 🔗 【闪客】名词诈骗!一口气拆穿Skill/MCP/RAG/Agent/OpenClaw底层逻辑
贯穿全文的🌰h3
不用害怕看不懂,最后会逐步讲解
这个图片贯穿全文,可以再开一个标签页分屏显示图片,边阅读正文边理解图片
💡 导语:LLM 与 Agent 的本质区别h2
Agent 不是 LLM 的替代品,而是它的 进化形态。
1. LLM:语言与推理引擎(会说,不会做)h3
LLM(大语言模型)能生成文本、推理问题、理解意图、输出结构化内容(如 JSON / Schema),甚至生成 SQL/代码。但它不能执行真实动作(写文件、下单、API 调用)、不能与系统交互、不能保存长期记忆、不能控制状态机,也无法稳定完成多轮复杂任务。
- LLM 的本质是一个超级语言补全器 + 世界模型。
- 示例: 当用户要求“帮我订一个明天飞上海的机票,预算 500 元以内”时,LLM 只会根据训练数据“猜测机票价格”给你几段建议,但不会去查真实航班。本质上,它是在 说 ,不是在 做。
2. Agent:让 LLM 变成“能行动的智能体”(会做)h3
Agent 是让 LLM 的“推理能力”在系统中运作起来的框架。Agent 必须具备完整闭环:感知 记忆 推理 工具调用 执行动作 观察结果 再推理 完成任务。
- Agent 的核心价值:完成任务,而不是回复。
- 示例: Agent 会识别意图 调用真实 API 查询航班 过滤预算范围 生成可购买方案。最终 Agent 的输出是找到符合预算的航班方案,而不是建议。
核心总结: LLM 只能“说”,Agent 才能“做”。
| 类别 | LLM | Agent |
|---|---|---|
| 推理 | ✔️ | ✔️ |
| 工具调用 | ❌ | ✔️ |
| 状态管理 | ❌ | ✔️ |
| 长期记忆 | ❌ | ✔️ |
| 对外行动 | ❌ | ✔️ |
| 自我修正 | ❌ | ✔️ |
| 多轮任务执行 | ❌ | ✔️ |
🛠️ 第二部分:Agent 的持续行动力——系统与循环h2
Agent 之所以能持续行动,是因为它是一套 “带状态的推理—行动循环系统”。
1. Agent 的四大核心能力h3
Agent 若要能“持续行动”,必须至少具备四类能力:
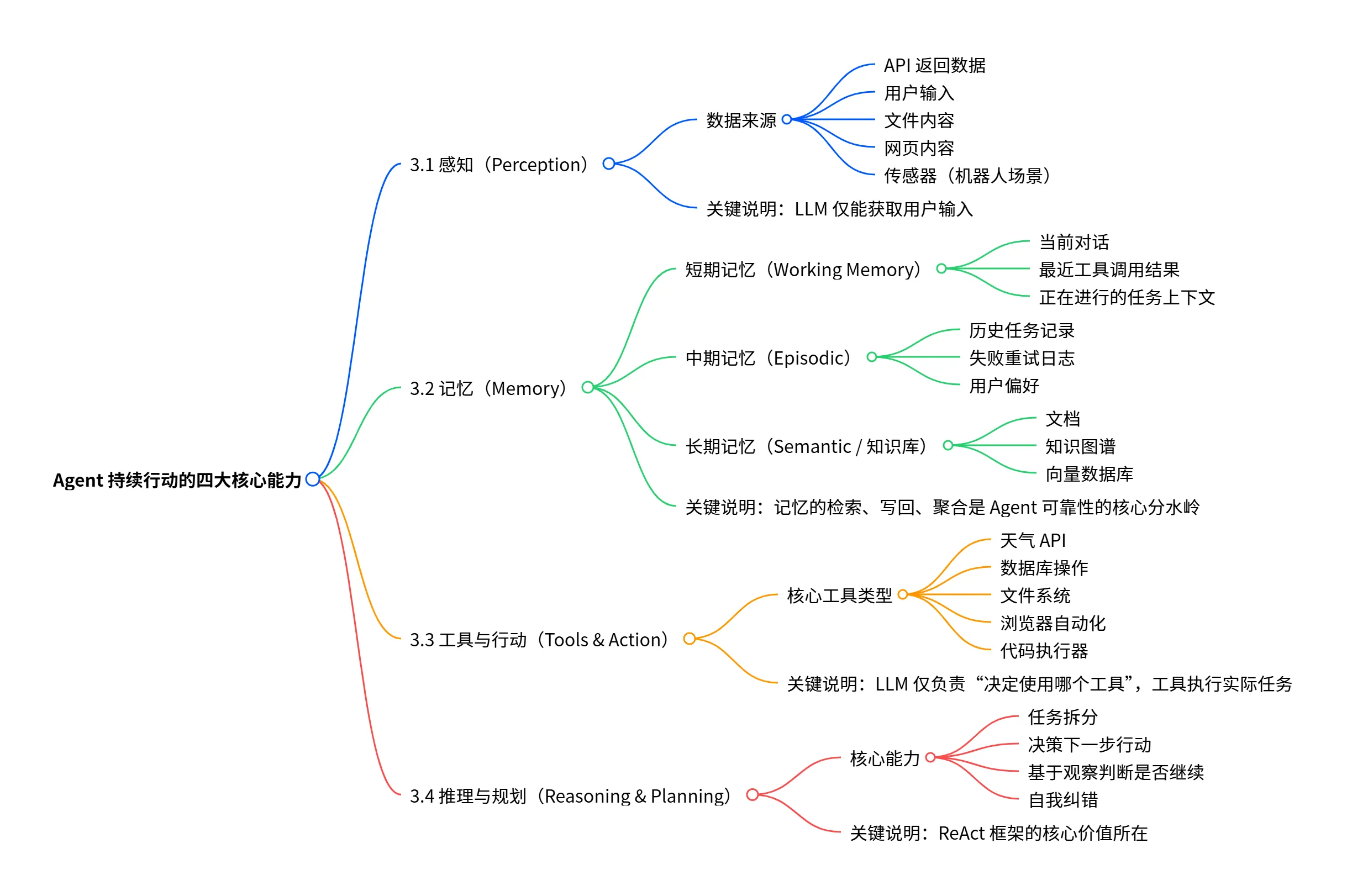
- 感知 (Perception): 接收环境输入。数据来源包括 API 返回数据、用户输入、文件内容等。
- 记忆 (Memory): 管理不同层级的状态和知识。长期记忆(文档、向量数据库)的检索、写入、聚合是 Agent 可靠性的核心分水岭。
- 工具与行动 (Tools & Action): LLM 仅负责 决定 使用哪个工具,工具负责 执行 实际任务。
- 推理与规划 (Reasoning & Planning): 核心能力在于任务拆分、决策下一步以及自我纠错。
2. Agent 的标准工作循环(案例详解)h3
下面是标准的 Agent 循环伪代码:
while not done: # 1. 读取 “状态” context = memory.retrieve()
# 2. 基于状态推理下一步 thought = LLM.plan(context)
# 3. 判断模型的意图是不是 “要执行工具” action = parse(thought)
# 4. 执行工具 result = tools.execute(action)
# 5. 将观察写入记忆(外部长期状态) memory.write(action, result)
# 6. 判断任务是否达成 done = check_goal(result)翻译成中文就是:Agent 的工作不是“一次调用模型”,而是一个循环过程。
| 步骤 | Agent 必要能力 | 作用 |
|---|---|---|
| 读取记忆 | 状态管理 | 让模型知道“我上一轮做到哪了” |
| 推理下一步 | 规划 | 决定下一步动作 |
| 执行工具 | 行动 | 让“语言输出”变成“真实动作” |
| 写入记忆 | 状态更新 | 保证下一轮不会遗忘 |
| 判断完成 | 收敛机制 | 避免无限循环 |
🧩 我们可以用一个例子理解这个步骤:自动化报销 Agent
假设要做一个公司内部的“报销助手 Agent”,它能:
- 解析用户上传的发票
- 自动分类
- 查预算
- 创建报销单
- 提交审批
它的每一步都严格按上面循环:
第一轮
- 读记忆:空
- 规划:用户上传了发票,我先 OCR
- 行动:调用
read_invoice() - 写记忆:发票金额 = 320, 类别 = 交通
第二轮
- 读记忆:发票金额、类别
- 规划:需要查预算剩余额度
- 行动:
get_budget(user_id)
第三轮
- 读记忆:预算 = 500
- 规划:可以创建报销单
- 行动:
create_ticket(320, "交通")
第四轮
- 读记忆:报销单编号
- 规划:提交审批
- 行动:
submit_approval(ticket_id) - 达成任务 → done
结论: 一个 Agent 是一套 “带状态的推理—行动循环系统”,循环 + 状态 才是核心。
3. Agent 的工程难点(真实开发会遇到的)h3
现实中做 Agent,远比“加个工具调用”难得多:
- 上下文窗口有限 → 需要分段检索、摘要
- 工具调用失败 → 需要回滚、重试逻辑
- 幻觉问题 → 需要验证器(verifier)
- 成本与延迟 → LLM 调用昂贵
- 长期记忆管理困难
- 权限管理与安全风险
所有成熟 Agent 框架(LangChain、Meta Agent、OpenAI Agent API)都在解决这些问题。 这就是为什么成熟的 Agent 框架变得如此重要。
4. 如何评价一个 Agent?h3
- 任务成功率
- 工具调用次数
- 延迟 / 调用成本
- 错误恢复能力
- 安全性与权限合规
- 可解释性(日志链路)
🔗 第三部分:从 Prompt 到 Function Calling 的演进h2
要让 LLM(大脑)指挥 Agent(身体)调用工具(手脚),必须解决 通信格式的稳定性 问题。
1. Prompt:早期 Agent 的通信基础h3
Prompt 分为 System Prompt(系统预设)和 User Prompt(聊天内容)。
- system Prompt:系统预设的,用来设定AI模型的角色、性格、行为边界、规则
用户不能随便更改system prompt,但网站也会提供一些设置,比如gpt里面有一个叫做customize chatgpt的功能, 用户可以在里面写下自己的偏好,这些偏好就会变成system prompt的一部分。
- user Prompt:我们与大模型的聊天内容
早期 Agent(如 AutoGPT)通过将工具的 自然语言描述 和调用规则(例如:“如果你想调用 XXX 工具,请返回 - 我要调用 + 工具名 + 参数”)写入 System Prompt,然后发送给 LLM。
Prompt 机制的局限性: LLM 本质是概率模型,容易出现忘记格式、缺少字段、JSON 不合法等问题。这迫使 Agent 必须写大量的“重试逻辑”来检查和修正格式。
2. Function Calling:标准化的工具调用方式h3
Function Calling 工作流程示意图如下所示,来源链接🔗https://help.aliyun.com/zh/model-studio/qwen-function-calling
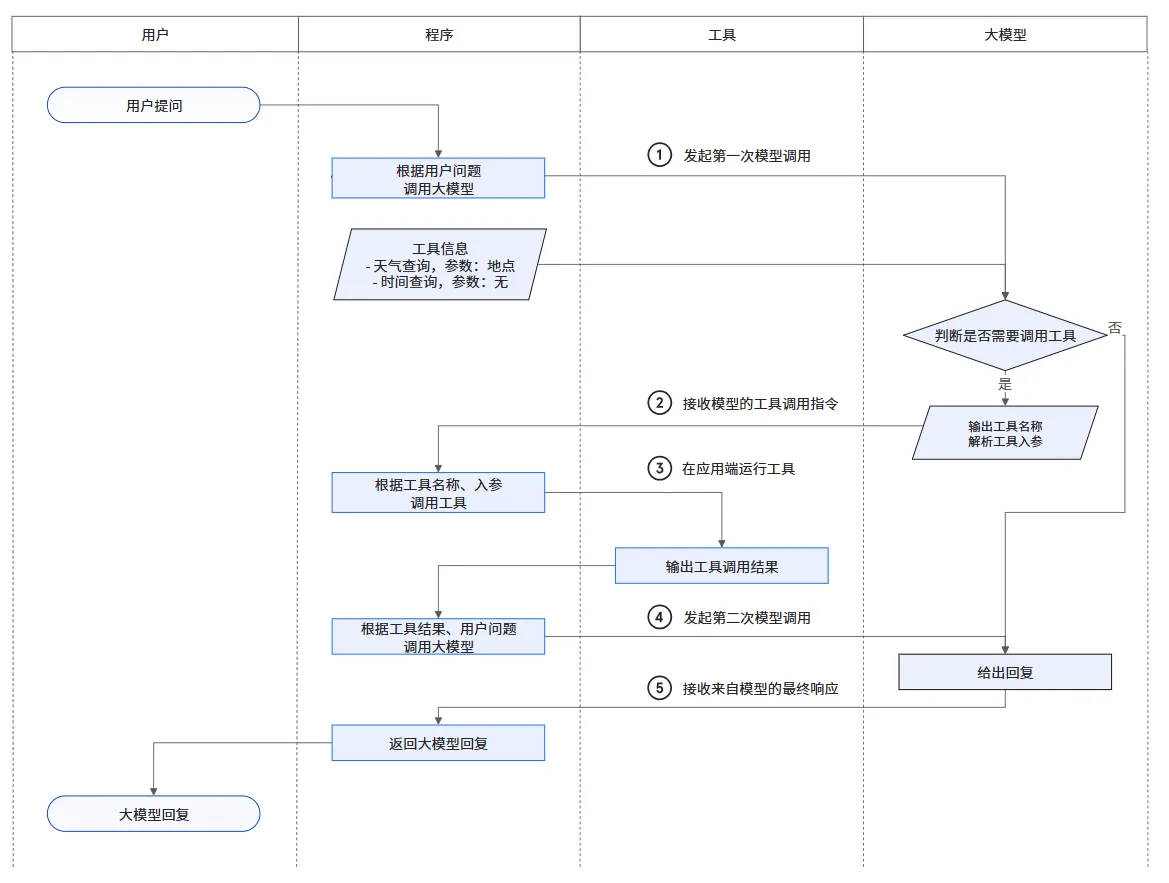
- 定义: 它是一种让 LLM 能够生成 结构化 JSON 来表达调用工具意图的能力。
- 机制: 它使用 JSON Schema 来标准化工具描述和返回格式。工具信息不再以自然语言形式存在。
- 优势: 现代大模型利用 约束解码(constrained decoding),只允许模型生成符合预定义 Schema 的 Token,从而在生成时就拦截格式错误。这节省了用户端重试带来的 Token 开销。
Function Calling 工作流程(参考图表):
- 程序(Agent)将工具信息(如天气查询的参数、地点、时间等)发送给大模型。
- 大模型判断是否需要调用工具,若需要,输出工具名称和解析的参数。
- 程序根据模型指令在应用中运行工具。
- 工具结果返回给程序,程序发起第二次调用,将结果带给大模型。
- 大模型根据工具结果给出最终回复。
LLM 返回的结构化指令示例:
{ "type": "call", "name": "search_web", "args": { "query": "CSgo 安装地址" }}当然Function Calling仍然不是完美的
虽然各大厂都支持 function calling,但:
- 每家厂商的格式略有差异
- 早期开源模型不支持
想写一个“跨模型通用 Agent”依然很麻烦
因此,目前市面上:system prompt + function calling 并存。
而且这只是 AI模型 ↔ Agent 之间的通信方式。接下来我们来讲 Agent ↔ 工具(Tool)之间的通信。
🤖 第四部分:Tools如何提供给Agent?MCP给出答案h2
Agent 与工具的解耦与标准化——MCP
Function Calling 解决了 LLM ↔ Agent 的通信问题,而 MCP (Model Context Protocol) 旨在解决 Agent ↔ 工具(Tool) 之间的通信标准化问题。
1. MCP 的概念与目标h3
- 定义: MCP 是一个通信协议,专门用来规范 Agent(MCP Client)和 Tools 服务(MCP Server)之间的交互。下面是Anthropic的官方定义:
- MCP is an open protocol that standardizes how applications provide context to large language models (LLMs). Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools. MCP enables you build agents and complex workflows on top of LLMs and connects your models with the world.
- MCP 是一个开放协议,用于标准化应用程序向大语言模型(LLM)提供上下文的方式。你可以把 MCP 想象成 AI 应用的 USB-C 接口——正如 USB-C 提供了一种将设备连接到各种外设和配件的标准化方式一样,MCP 提供了一种将 AI 模型连接到不同数据源和工具的标准化方式。借助 MCP,你可以在 LLM 之上构建智能体和复杂工作流,并将你的模型与外部世界相连接。
- 如何理解:
- 应用程序:集成了 LLM 的具体应用。包括各家大模型的在线对话网站、集成了大模型的IDE(如 Claude desktop)、各种 Agent(比如 Cursor 就是一个 Agent)、以及其他接入了大模型的普通应用。
- 上下文:指的是模型在决策时可访问的所有信息,如当前用户输入、历史对话信息、外部工具(tool)信息、外部数据源(resource)信息、提示词(prompt)信息等等(这里重点只讲工具)。
2. MCP架构h3
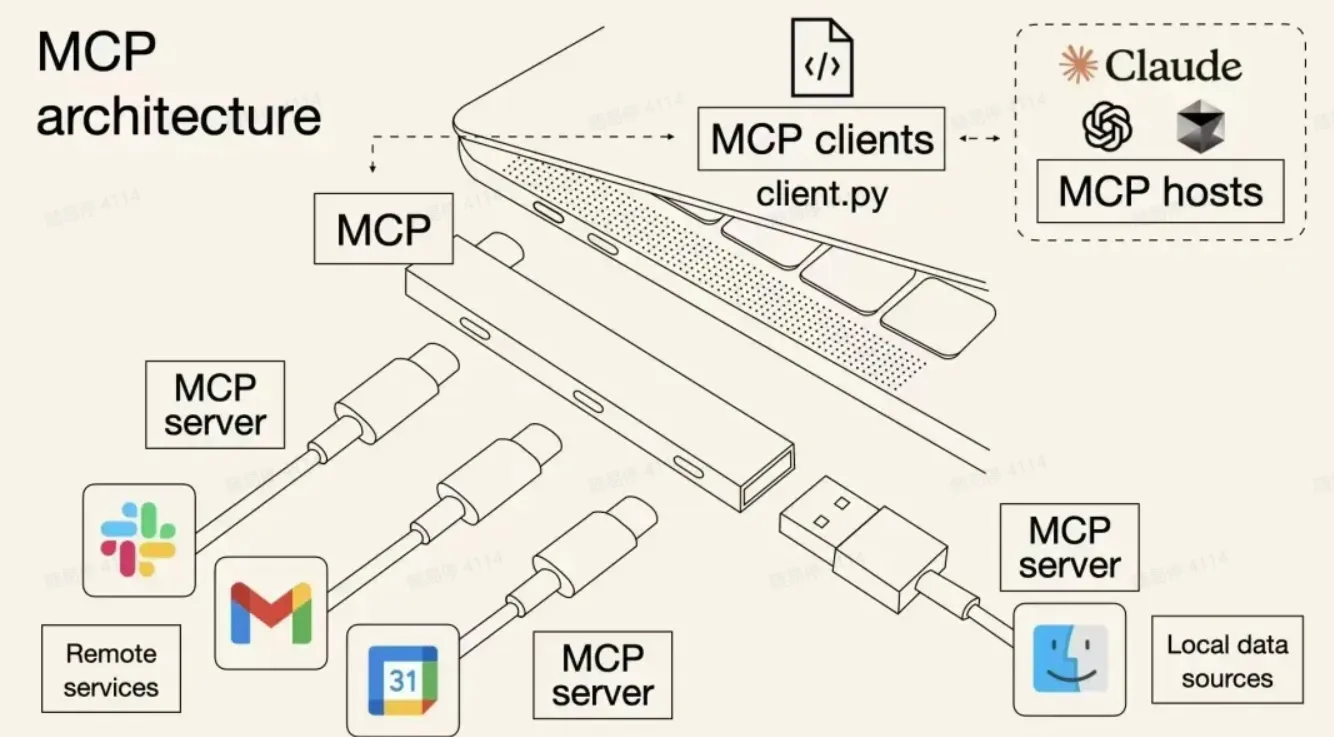
MCP遵循客户端-服务器架构,其中 MCP Host——Claude Code 或 Claude Desktop 等AI应用程序——与一个或多个MCP Server 建立连接。MCP 主机通过为每个 MCP Server 创建一个 MCP Client 来实现这一目标。每个 MCP Client 都与相应的 MCP Server 保持专用的一对一连接。MCP架构的主要组成者是:
- MCP Host:协调和管理一个或多个 MCP Server 的人工智能应用程序
- MCP Client:一个组件,用于维护与 MCP 服务器的连接,并从 MCP 服务器获取上下文,供 MCP 主机使用
- MCP Server:一个为 MCP Client 提供上下文的程序
例如:Visual Studio Code 充当 MCP 主机。当 Visual Studio Code 建立与MCP服务器(如Sentry MCP服务器)的连接时,Visual Studio Code 运行时实例化了维护与Sentry MCP服务器连接的MCP客户端对象。当Visual Studio Code 随后连接到另一个MCP服务器时,例如本地文件系统服务器,Visual Studio Code 运行时实例化一个额外的MCP客户端对象来维护此连接,从而保持MCP客户端与MCP服务器的一对一关系。
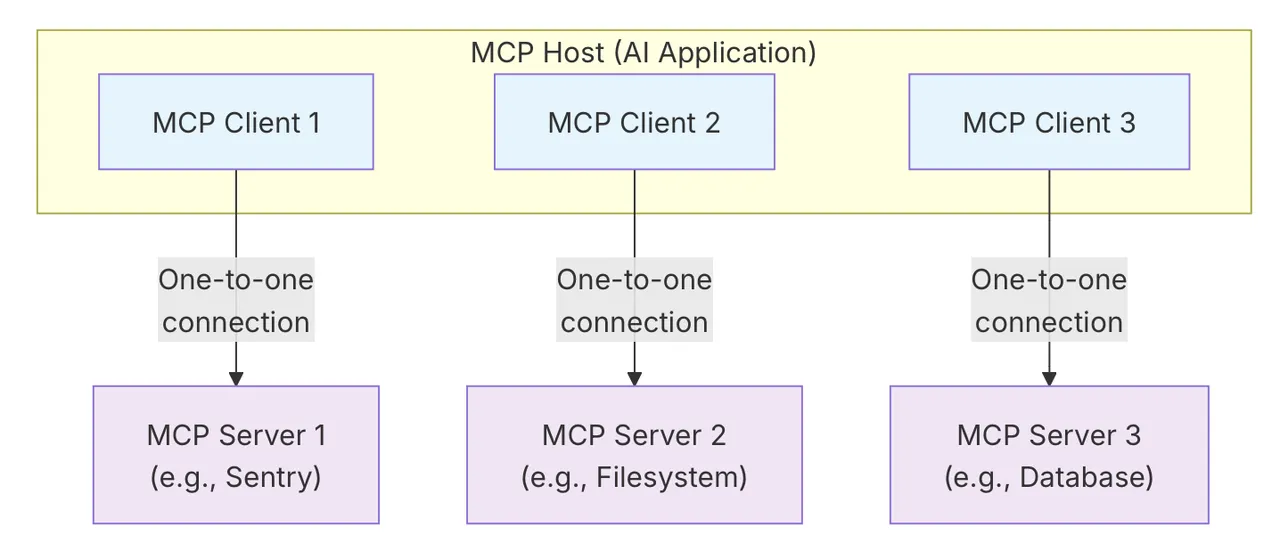
- 角色分工:
- Agent (MCP Client): 项目经理,负责编排、转达和执行。
- MCP Server (工具服务): 外包工具团队,提供实际能力。
- MCP Server 提供的内容: 可以提供函数调用的形式(Tool),类似文件读写的服务(Resource),或者提示词模板(Prompt)。
- 优势: MCP 统一了 Agent 与外部世界的能力接口。它带来的优势包括工具复用、统一格式、工具与 Agent 彻底解耦、跨平台以及模型无关性。
- 解决了工具介入的冗余开发问题:对于同一个功能可能对于多个大模型有多个实现,你需要做多套工具才行
- 解决了工具复用难的问题:环境问题导致copy的代码不一定能用,很多工具也并非会提供给你源码,跨语言的代码copy了也没法用
3. Function Calling 和 MCP 的互补关系h3
Function Calling 和 MCP 是不同层面上的 互补关系,不存在取代。
- Function Calling: 是 LLM 内部 的输出机制,表达调用意图。
- MCP: 是 LLM 外部 Agent 与工具之间的通信标准。
- 协同方式: Agent 会将 MCP 工具的标准化定义转换为 LLM 可以理解的 Function Calling Schema 喂给 LLM。LLM 利用 Function Calling 发出指令,Agent 再利用 MCP 执行指令。
Agent (MCP Client) 执行 MCP 调用示例:
# Agent (MCP Client) 执行代码片段# 1. 接收 LLM 指令(Function Calling JSON)llm_instruction = {"name": "get_weather", "args": {"city": "Beijing"}}
# 2. 通过 MCP 协议调用 MCP Server 上的工具# (MCP Client 负责将 JSON 参数传递给工具服务)weather_data = mcp_client.call_tool( tool_name=llm_instruction['name'], params=llm_instruction['args'])
# 3. 将 weather_data 发送回 LLM 进行总结📈 第五部分:综合案例——MCP 架构下的 Agent 工作流h2
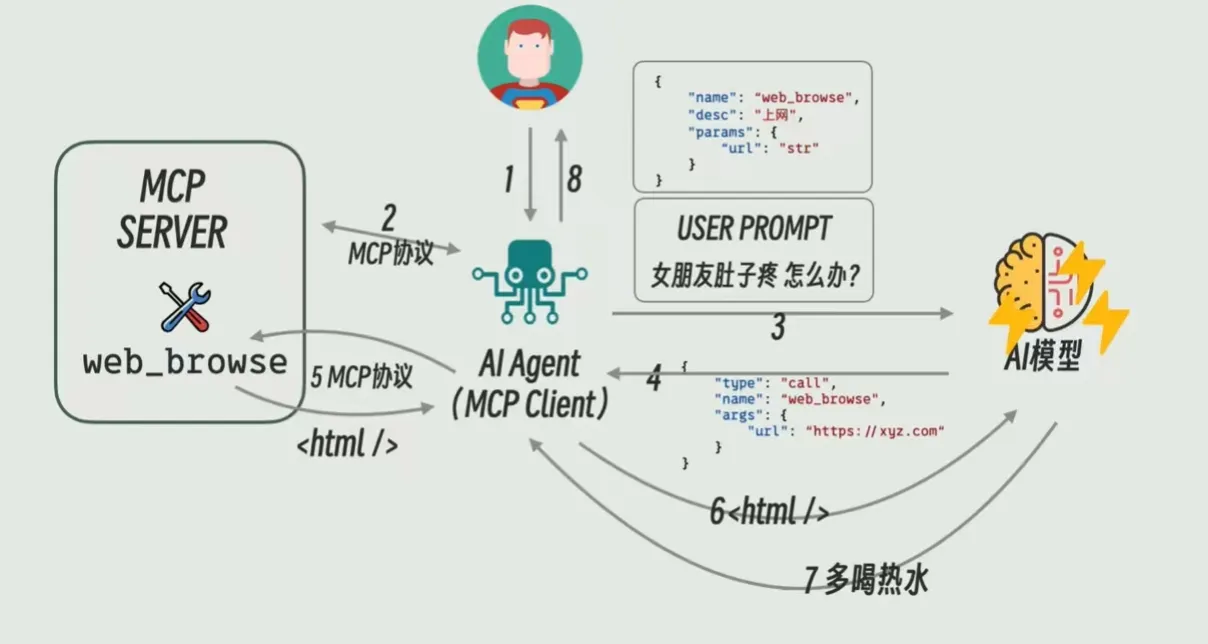
我们通过一个完整的流程,来理解所有组件是如何协作的:
- 我听说女朋友肚子疼,于是问AI agent或者说MCP client, 我女朋友肚子疼应该怎么办?
- Agent把问题包装在user prompt中,然后agent通过MCP协议从MCP server里面获取所有tool的信息
- Agent把这些tool的信息转化成system prompt或者转化成function calling的格式,然后和用户请求user prompt一起打包发送给AI模型。
- AI模型发现有一个叫做web_browse的网页浏览工具可以用,于是通过普通回复或者function Calling格式产生调用这个tool的请求,希望去网上搜索答案。
- Agent收到了这个请求之后,通过MCP协议去调用MCP server里的web browse工具。Web browse访问指定的网站并将内容返还给agent
- agent再转发给AI模型
- AI模型根据网页内容和自己的头脑风暴生成最终的答案---多喝热水,再返还给agent。
- 最后由agent把结果展示给用户
综上就是system prompt、user prompt、AI agent、agent to function calling、MCP、AI模型之间的联系与区别了
他们不是彼此取代的关系,而是像齿轮一样,一起构成了AI自动化协作的完整体系
再举一个🌰
用户(客户) → Agent(项目经理) → 模型(顾问) → MCP Server(外包工具团队)
- 用户把需求告诉项目经理(Agent)。
- 项目经理不会自己想答案,于是把需求转给顾问(AI 模型)。
- 同时,项目经理还会把手上所有“可用外包团队”(MCP Server 提供的工具列表)发给顾问看。 早期,项目经理只能用自然语言解释这些团队的服务范围(system prompt),说不清楚时顾问就会误解。 后来大家统一用一份结构化的“外包团队服务手册”(Function Calling / JSON Schema),顾问就不会理解错误。
- 顾问分析后告诉项目经理:“要完成需求,需要叫这个外包团队(某个 tool)来做”。
- 项目经理自己去调用外包团队的接口(MCP Server),拿到结果后再给顾问复核。
- 顾问确认结果满足需求后,项目经理把最终成果交给用户。
🔨 第六部分:Skills来了h2
Skills是对能力的封装编排,且可以对能力所需要的资源进行管理
难免会和MCP做对比,MCP Tools像是能力而Skills是方法是经验
Skills的出现给我一种自然语言编程的感觉,像是被武装的prompt,也像是一个特殊的工作流
一个Skill由哪几个部分组成?h3
根据Anthropic的定义一个完整的Skill结构包含三个核心方面,物理形式上表现为一个包含SKILL.md的目录
- 元数据metadata:用于让Agent判断在什么时候调用
- Name:技能唯一标识符
- Description:精简自然语言描述,告诉模型这个技能是干什么的
- 程序性知识procedural Knowledge:类似于SOP,即具体的SKILL.md内容
- 步骤指引:详细的自然语言指令,指导Agent第一步做什么、第二步做什么
- 规则约束:必须遵守的限制
- 示例样例:展示输入和理想输出的例子,帮助模型对齐预期
- 资源与工具
- 模板Templates:预设输出格式(如markdown报告模板、代码框架)
- 脚本Scripts:供Agent调用的Python脚本或SQL查询文件
- 参考文档Reference:特定领域的知识文档(如API文档、品牌手册、用户手册等)有点像RAG知识库的感觉
Skill的效能h3
- 上下文优化与成本控制
- 渐进式披露三层结构:元信息->指令层->资源层。Skill始终加载元数据,在选择好了具体要用的Skill之后再按需加载指令,当指令涉及到某些资源的时候再按需加载资源
- 减少干扰:上下文越长模型越容易迷失,Skill机制确保了在执行特定任务时Context中只有最相关指令
- 节省Token:对于长对话或复杂任务,不重复发送无关Prompt指令能直接降低API调用成本
- 行业标准化与质量保证
- 固化最佳实践SOP:将行业最佳实践显化为Skill,例如一个代码审查Skill可以强制要求先检查安全性再检查性能最后检查风格
- 减少幻觉:Skill通常包含样本示例,让模型在受控范围内发挥
- 确定性提升:通过在Skill添加约束可以答复提高输出格式的一致性
- 工程化与可维护性
- 模块化解耦:相较于拖拉拽工作流牵一发动全身,Skill实现了解耦,可以将能力单独编排维护互不影响
- 便于版本管理:Skill是一个纯文本文件,非常适合Git来做版本控制
- 可移植性与复用性:
- 即插即用:对于重复需求可以较好的迁移与复用
- 生态系统:为Agent的发展打下基础
❓ Q&A 整合h2
记录我在学习的过程中产生的疑问,分享出来,希望能帮到其他读者
Q1:Agent 里面是不是一定包含 LLM?为什么有些图把它们画开?h3
A:不一定,但现代 AI Agent 是包含 LLM的。
- Agent 比 LLM 更广义: 广义的 Agent 指的是能感知环境、做出决策并采取行动的系统。传统 Agent(如游戏 NPC、专家系统)可以不包含 LLM。
- 现代 Agent: 特指 LLM-based Agent,LLM 是核心组件。架构上:通常是分开部署的。 在概念层面,我们说“这个 Agent 很聪明”,是因为它包含了一个 LLM。 但在工程/代码层面,Agent 往往是一段控制代码(Python/Java等写成的程序),它通过 API 去调用 LLM。
- 架构分离的原因: 在架构图中,为了区分职责,习惯把 “负责干活的程序/编排器” 标记为 Agent/Client(躯干和四肢),把 “负责思考的模型” 标记为 Model/LLM(大脑)。它们通常物理上分开部署,Agent 通过 API 调用 LLM。
- 核心结论: LLM 是 Agent 的大脑,而 Agent 是一个更大的系统范畴,在这个领域有一个著名的公式(由 OpenAI 的 Lilian Weng 总结):
Q2:System Prompt 何时传入 LLM?它会消耗 Token 吗?h3
A:System Prompt 每次对话都会传入,并且消耗 Token。
- 传输时机: System Prompt(系统预设的规则和角色)和 User Prompt(用户聊天内容)会一起打包发送给 AI 模型。
- Token 消耗: 它们都属于上下文,会消耗 Token。
- 包含内容: System Prompt 用来设定模型的角色、行为边界和规则。在 Function Calling 出现前,它也会包含工具的自然语言描述。
Q3:如何解决工具过多导致上下文超限的问题?h3
A:工具不是“塞进 prompt”,而是“筛选后以结构化方式注入”。
现代 Agent 系统采用多种优化策略:
- 按需注入(On-Demand Injection): Agent 会根据用户的任务意图(例如提到“浏览网页”),只加载相关的少量工具。
- 向量检索选择(Vector-Based Tool Retrieval): 将所有工具描述向量化,当用户提出需求时,Agent 检索出 Top-K(通常 3~10 个)最相关的工具注入模型。
- 结构化字段传入: 在许多主流 API 中,Function/Tool Calling 的 Schema 是一个独立字段,不以系统提示词形式写入 Prompt,模型内部使用结构化约束解析调用,减少对上下文容量的压力。
Q4:Function Calling (函数调用) 与 MCP 是什么关系?谁取代了谁?h3
A:它们是不同层面上的互补关系,不存在取代。
- Function Calling: 是 LLM 内部 的输出机制。它让 LLM 能生成结构化 JSON 来表达调用意图。
- MCP: 是 LLM 外部 Agent 与工具之间的通信标准。它定义了工具如何向 Agent 暴露自身能力。
- 协同方式: Agent 将 MCP 工具的标准化定义转换为 Function Calling Schema 喂给 LLM。LLM 生成指令,Agent 利用 MCP 执行指令。
Q5:MCP 是直接给 LLM 使用的协议吗?h3
A:不是。MCP 是 Agent 与工具之间的标准通信协议,是 Agent 的接口,不是 LLM 的接口。
LLM 只负责生成文本/JSON 指令,它本身无法主动发起交互。实际的调用和执行(即通过 MCP 与 Tool Service 通信)是由 Agent(MCP Client)负责的。
🚀 总结:Agent 的本质与未来h2
AI Agent 是一个能感知、能规划、能行动、能调用工具、能观察、能自我纠错、能持续多轮执行的 智能行动系统。
- LLM 是大脑,Agent 是生命体。
- 未来的软件范式将是 从写代码 到写意图,从编程 到引导。