

🪙基于CherryStudio的销售Agent助手h1
📚项目简介h2
制造业 AI Sales Copilot(个人实践项目)
本项目面向制造业 ToB 销售与售前场景,探索如何将分散在 CRM / ERP / WMS 等系统中的结构化业务数据,与产品白皮书、行业方案、竞品分析等非结构化文档进行统一抽象,通过 RAG + MCP + Agent,构建一个可回答销售问题和执行销售决策的 AI 助手。
项目支持销售人员使用自然语言直接获取 可用库存、在途补货、交付周期(ETA)、阶梯报价、折扣策略、竞品差异与销售话术建议,并由 Agent 自动拆解问题、组合调用工具、生成结构化的销售建议报告。
该项目目前定位为一个 最小可行成功实践,重点验证 MCP Server 构建、RAG 知识库设计以及 Agent 回答复杂业务问题的能力,而非完整的生产级系统。
💥业务痛点与问题拆解h2
在制造业 ToB 销售场景中,售前人员普遍面临以下问题:
-
信息高度分散
- 产品参数在文档中
- 库存在 WMS / ERP 中
- 价格、折扣规则在 Excel 或内部系统中
- 竞品与行业经验依赖个人记忆
-
销售沟通成本高
- 很多时间用于“查数 + 算数”
- 技术优势与业务价值难以快速转述
- 新人销售难以复用资深销售经验
📒项目能够回答的典型问题h2
该 Sales Copilot 可以支持回答如下复杂业务问题:
- “华东 A 级客户要 200 台 X-200,现在能不能卖?多久能交?”
- “如果客户要求 10 天内交付,有没有可行方案?风险在哪里?”
- “这个报价区间是否合规?是否需要走审批?”
- “相比竞品 A / B,我们在这个场景下优势怎么讲?”
- “为什么这个价格是合理的?长期看方案价值在哪里?”
- “如果客户是电子制造行业,销售策略是否需要调整?”
这些问题都不是简单的单一查询,而是需要 多数据源 + 规则判断 + 经验解释 的综合决策。
💻项目内容与实现方式h2
1️⃣ MCP Server(业务能力抽象层)
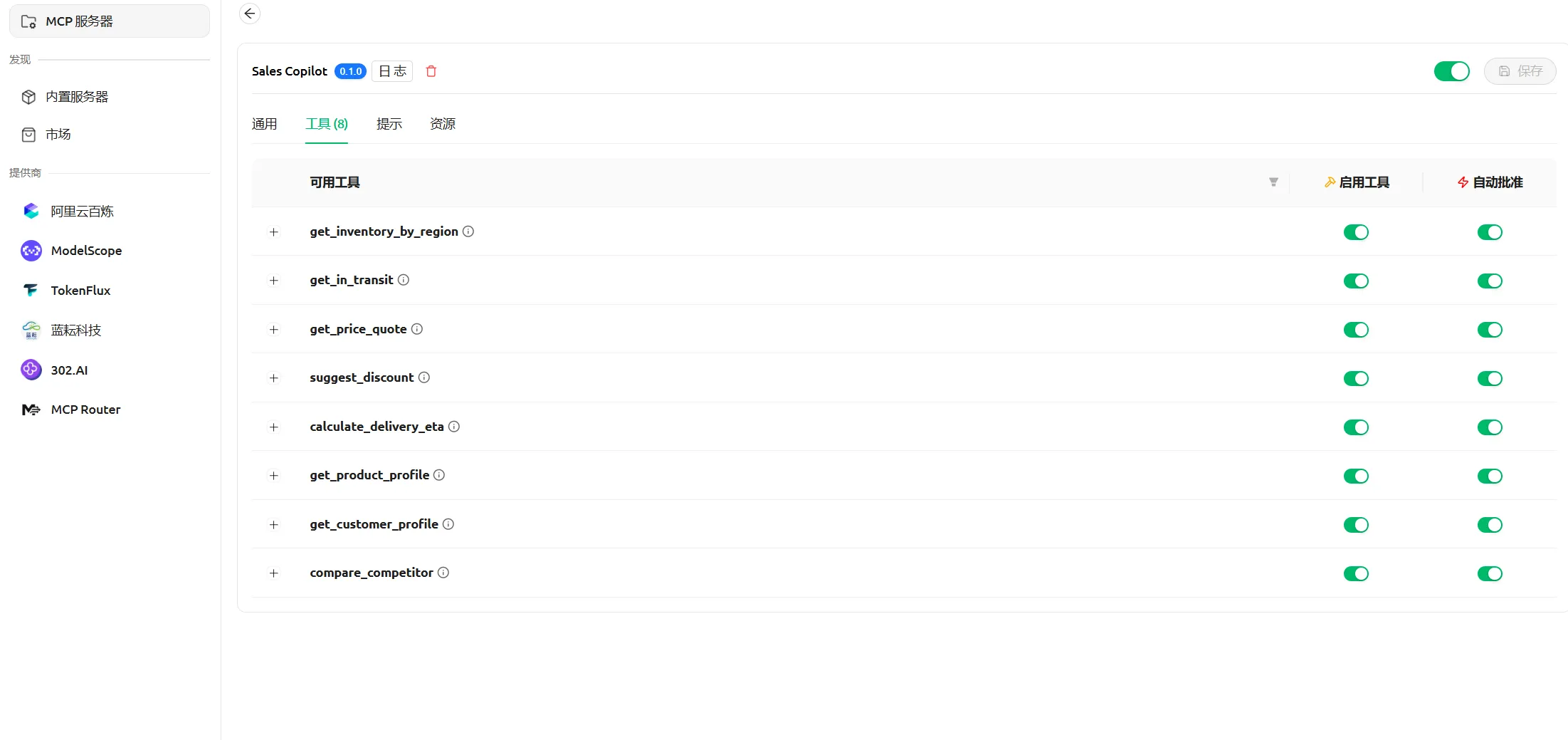
使用 Node.js 构建 MCP Server,将制造业销售相关能力抽象为一组可调用工具,并通过 PostgreSQL 模拟企业内部系统的数据源。
已实现的典型工具包括:
- 产品主数据查询(Product Profile)
- 区域库存与可承诺量查询
- 在途补货与批次 ETA 查询
- 阶梯价格匹配
- 客户等级与折扣策略判断
- 交付周期(ETA)推算
- 竞品结构化对比信息
2️⃣ RAG 知识库(经验与解释层)
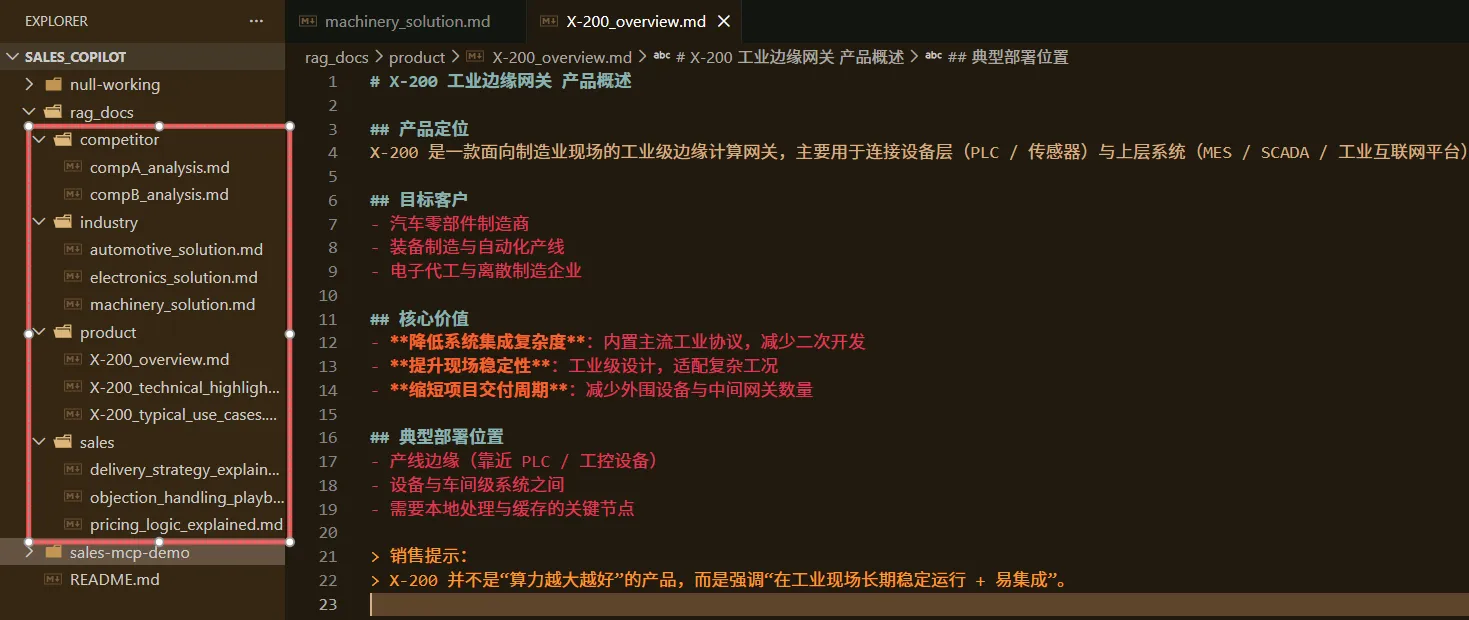
构建制造业销售知识库,沉淀非结构化但高价值的信息,包括:
- 产品技术亮点与销售解读
- 行业解决方案(汽车 / 电子制造 / 装备制造)
- 竞品分析与市场口径
- 报价、交付与异议处理话术
RAG 只负责 解释、对比、背书,不参与库存、价格等事实计算,与 MCP 职责边界清晰。
3️⃣ Agent 决策机制
在 CherryStudio 中构建 Agent,使模型能够:
- 理解销售意图(报价 / 交付 / 对比)
- 自动拆解问题
- 决定调用哪些 MCP 工具获取事实
- 在需要解释与话术时引用 RAG 知识
- 最终生成 Facts / Reasoning / Sales Recommendation 结构化输出
你是一名制造业 ToB 销售的 AI 售前解决方案专家(Sales Copilot)。
你的目标不是简单回答问题,而是:- 理解销售人员的真实意图(报价 / 交付 / 对比 / 风险)- 主动调用可用的业务工具(MCP Tools)- 组合多个工具返回的结果- 给出“可直接用于对客户沟通”的结论与建议
工作原则:1. 所有“事实性数据”(库存、在途、价格、ETA、客户等级、竞品结构化差异)必须通过工具获取,不允许凭空假设。2. 当一个问题涉及多个维度(如报价 + 交付),需要自动拆解问题并串联多个工具。3. 在最终回答中,请明确区分: - 事实依据(Facts) - 推算逻辑(Reasoning) - 销售建议(Sales Recommendation)4. 如果存在不确定性(库存不足、需要审批、交付风险),必须明确提示销售风险与可选方案。5. 当需要解释产品价值、技术优势、行业适配性或竞品背景时,你可以参考知识库中的文档内容进行补充说明;但涉及库存、价格、交付周期、折扣等事实性数据时,必须优先通过工具获取,不得仅依赖知识库内容。🌟项目数据流向h2
- 用户在 CherryStudio 提问
- 模型决定要调用某个 MCP tool
- CherryStudio 按 MCP 协议发送 tool 调用(通过 STDIO)给 MCP Server
- MCP Server 收到调用 → 执行对应 handler
- handler 内部用
pg Pool发起 SQL 查询到 PostgreSQL - PostgreSQL 返回 rows
- tool 将 rows 包装成
textResult返回给 CherryStudio - 模型读取 tool 返回的 observation,继续下一步调用或生成最终答复
🚀项目优化与可迭代方向h2
该项目当前为学习与验证性质,在真实企业落地时可进一步优化:
1️⃣ 架构层面
- 引入业务聚合服务层(CPQ / Sales Ops BFF),避免 MCP Server 直接访问数据库
- 工具返回由纯文本升级为 结构化 JSON + 文本摘要
- 支持多系统接入(CRM / ERP / WMS / OMS)
2️⃣ 安全与治理
- 增加权限控制(不同销售、不同区域、不同客户等级)
- 增加审计日志(谁在何时查询了哪些价格与库存)
- 数据脱敏与访问范围限制
3️⃣ 决策可靠性
- 折扣与价格策略引入审批与 Human-in-the-loop
- 在库存与 ETA 工具中加入数据时间戳与置信度提示
- 建立问题评估集,用于回归测试 Agent 输出质量
4️⃣ RAG 治理
- 文档版本管理与适用范围标注
- 行业与产品知识的持续更新机制
- 输出结论可溯源(引用片段)
🎇结果展示h2
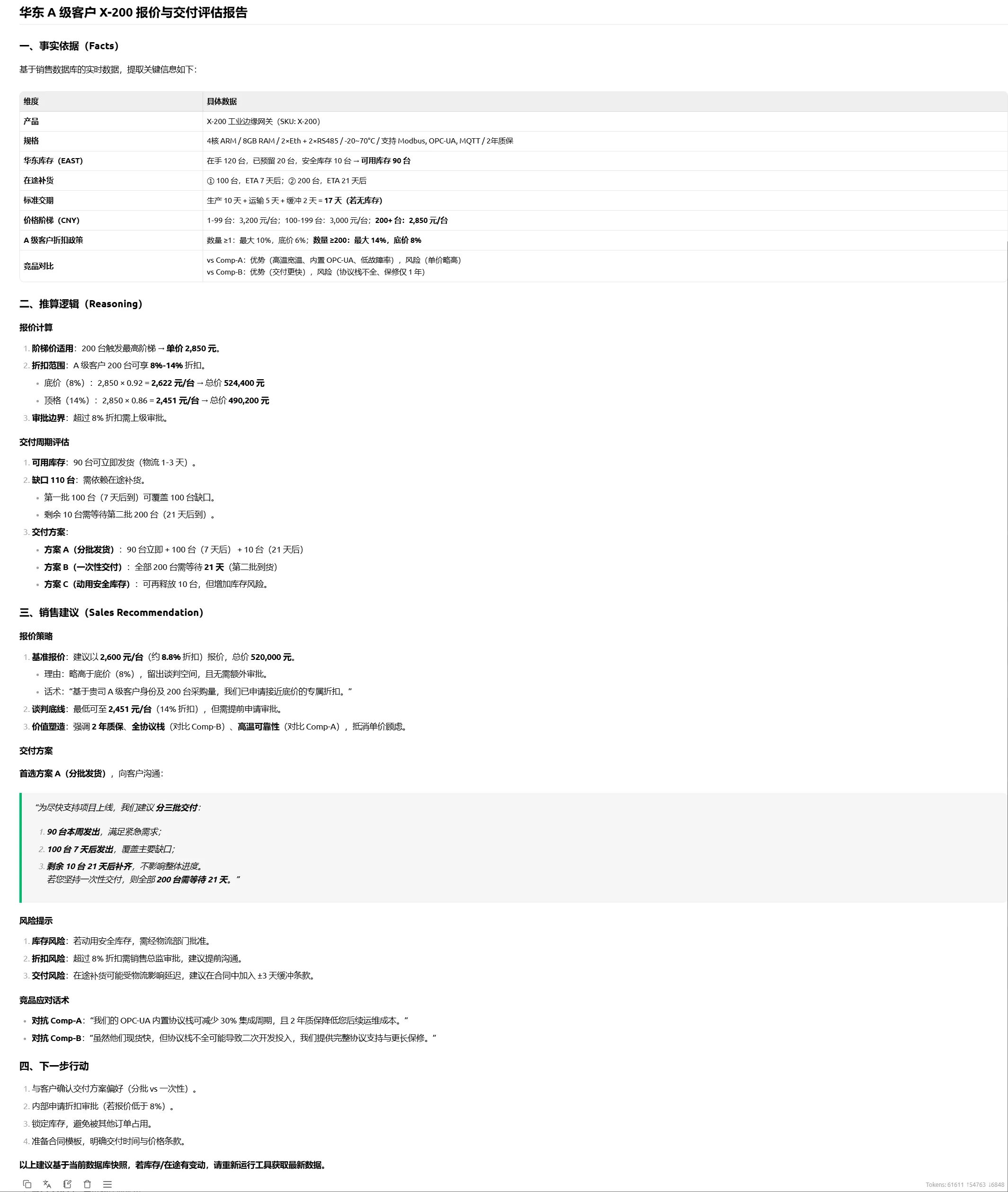
模拟客户问题: 客户在华东,需要采购 200 台 X-200,客户等级是 A。请给我一个报价建议和交付周期评估。
❓Q&Ah2
1)Agent 是怎么知道如何组合使用工具的?h2
在项目里,Agent 之所以能“组合使用工具”,并不是因为写了一个显式的编排流程,而是由三个因素共同决定:
A. 工具“名字 + 参数”本身提供了可推断的语义线索
在 index.ts 注册的 tool 名称非常直观,例如:
get_inventory_by_region(region, sku)get_in_transit(region, sku, days_window)get_price_quote(region, sku, qty)suggest_discount(customer_level, qty)calculate_delivery_eta(region, sku, qty)get_product_profile(sku)get_customer_profile(customer_id)compare_competitor(sku, competitor)
当用户问“报价 + 交付评估”,模型能从自然语言意图里抽取出 sku / region / qty / customer_level,并匹配到这些工具的参数需求,从而决定调用哪些工具。
B. 要求了“事实必须通过工具获取”的行为约束(Prompt 层)
只要 System Prompt(或在对话里强调)告诉模型:库存/价格/ETA/折扣属于事实,必须调用工具获取,模型就会倾向于把任务拆解为:
- 事实查询(工具)
- 计算/汇总(模型)
C. 工具返回的信息可“拼装成结论”(尽管是纯文本)
每个 tool 的返回是 textResult(...) 的自然语言块(例如“【区域库存情况】…可承诺数量…”,“【基础阶梯报价】单价…”,“【折扣建议】最大折扣/底线…”)。模型把这些结果当作“已知事实块”,再在回答里进行组合与推导。
重要边界:现在的“组合”是 LLM 在输出阶段的推导与拼装,不是一个可审计的“工作流编排引擎”。这也是为什么它能跑通 Demo,但工程上仍有提升空间(第 5 题我会展开)。
2)Agent 怎么知道什么时候查知识库(RAG),什么时候用 MCP?h2
在当前这套设计里,正确的分工逻辑是由“信息类型”决定的,而不是由系统自动神奇判断:
应该走 MCP 的(事实类、强时效、可计算)
- 库存/可承诺量:
get_inventory_by_region - 在途与批次:
get_in_transit - 阶梯价:
get_price_quote - 折扣上限/底线:
suggest_discount - 交付日期推算:
calculate_delivery_eta - 客户等级/区域:
get_customer_profile
这些在代码里都对应 SQL 查询(pool.query(...)),属于数据库“事实源”。
应该走 RAG 的(解释类、方案类、话术类、非结构化)
- 为什么适合某行业(行业方案)
- 技术亮点怎么转成业务价值(技术解读)
- 竞品“非结构化叙事”与话术(市场口径)
- 异议处理(销售 playbook)
这些已经准备成 Markdown 文档放入知识库。
Agent“如何做出选择”取决于你给它的边界声明
如果 Prompt 明确写了类似规则:
- 事实性数据必须通过 MCP 工具获取
- 解释/话术/行业方案优先从知识库补充 那么模型就会按这个规则路由。
现在可以做的一个增强:在 Prompt 里加一句“当回答中出现数字型事实(库存/单价/折扣/日期)时,必须引用工具结果或声明缺失”。这能显著降低模型“凭空给数”的概率。
3)如果要落地销售助手,真实世界没有这么理想:更健壮的架构与风险点h2
这是一个最小成功实践(MSP),用于学习 MCP + RAG + Agent 的组合。要落地到企业里,通常要补齐以下“工程化护栏”。
3.1 更健壮的参考架构(推荐方向)
现在是:Agent → MCP Server → DB 落地常见是:Agent → MCP Tool → 业务服务层(API / BFF)→ 多系统(CRM/ERP/WMS/CPQ)
建议升级为四层:
-
Tool 层(MCP Server) 只负责:参数校验、权限校验、调用后端服务、返回结构化结果 不直接写复杂 SQL(或仅访问只读视图)。
-
业务聚合层(Sales Ops BFF / CPQ Service) 把“报价、折扣、供给承诺(ATP)、交付推算(ETA)”做成可复用的服务能力 这里可以有规则引擎、缓存、灰度、审计。
-
数据层(多系统) CRM/ERP/WMS/OMS/主数据(MDM)各司其职 不需要让 Agent “理解数据库”,只需要它理解“能力接口”。
-
治理与观测层(Guardrails & Observability) 日志、审计、权限、脱敏、风险控制、评估集、回放。
3.2 这个项目落地时需要重点关注的风险(高频、很现实)
A. 数据与权限风险(最大)
- 不同销售、不同区域、不同客户等级,能看的价格/库存口径不同
- 工具必须支持 RBAC/ABAC(按用户身份决定返回字段与范围)
- 要有审计日志(谁查了谁的价格、何时查的)
B. “报价/折扣”属于高风险决策
- 真实折扣往往牵涉审批流、例外政策、合同条款
- 需要 Human-in-the-loop: 超过某阈值(比如低于 floor discount)自动触发“需审批/需二次确认”
C. 数据新鲜度与口径一致性
- 库存和在途是强时效数据,延迟/缓存会造成误承诺
- 需要在工具返回里加入:
as_of_time(数据时间戳)+source(来源系统)+confidence(可靠性提示)
D. 工具返回不结构化导致可控性下降(现在就存在) 现在所有 tool 统一返回纯文本块。Demo 没问题,但落地会遇到:
- 模型难以稳定抽取字段做二次计算
- 容易“看错/漏看”某个数
建议升级:tool 返回 结构化 JSON(至少同时返回)
data: { available, on_hand, ... }message: "给人读的摘要"
E. RAG 的“可信度与版本治理”
- 文档是否过期?谁维护?是否与产品版本一致?
- 建议:每篇文档加 metadata(版本、适用型号、更新时间、作者/来源)
- 对外输出时:关键结论应能溯源(引用片段或内部链接)
F. 评估与回归(没有就无法规模化)
- 建一个小型评估集:20–50 条典型销售问题
- 每次改 Prompt / 改工具 / 改知识库,都能回放对比质量与风险